Attention Is All You Need
Vaswani et al. · NIPS 2017 · arXiv:1706.03762
Abstract
Key Numbers at a Glance
1. Introduction
Prior to the Transformer, the dominant approaches to sequence modeling were recurrent neural networks (RNNs) — specifically LSTMs and GRUs. These models process sequences token-by-token, maintaining a hidden state that is updated at each step.
ht depends on ht-1, so you cannot process position 10 until positions 1–9 are done. This becomes a critical bottleneck at long sequence lengths.
Attention mechanisms were already used alongside RNNs to handle long-range dependencies without regard to distance. But they were always used in conjunction with a recurrent architecture.
2. Background
Earlier attempts to reduce sequential computation used convolutional neural networks (ByteNet, ConvS2S). In those models, the number of operations to relate two positions grows with their distance — linearly for ConvS2S, logarithmically for ByteNet.
Self-attention (intra-attention) relates different positions of a single sequence to compute a representation. It had been used in reading comprehension, summarization, and textual entailment tasks.
3. Model Architecture
The Transformer follows the standard encoder-decoder structure. The encoder maps input (x₁, …, xₙ) to continuous representations z = (z₁, …, zₙ). The decoder generates output (y₁, …, yₘ) one element at a time, auto-regressively.
Figure 1: The Transformer model architecture — encoder (left, blue) and decoder (right, purple) each composed of 6 identical layers.
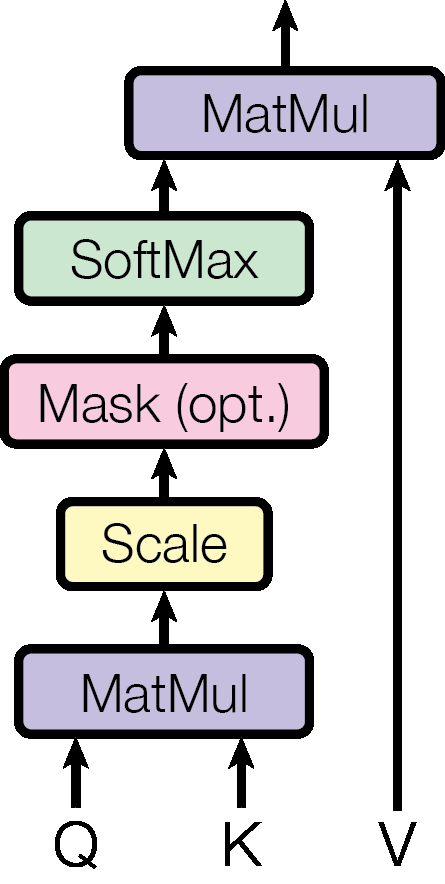
Figure 1b: Full Transformer architecture in detail — showing encoder (left) and decoder (right) with Nx repetition of identical layers, input/output embeddings, positional encoding, and cross-attention connections.
3.1 Encoder and Decoder Stacks
LayerNorm(x + Sublayer(x)). The residual connection allows gradients to flow unchanged through the network, enabling training of deep stacks.
3.2 Attention
An attention function maps a query and a set of key-value pairs to an output. The output is a weighted sum of values, where weights come from the compatibility of the query with each key.
3.2.1 Scaled Dot-Product Attention
Queries and keys have dimension dk; values have dimension dv. The scaling factor 1/√dk prevents the dot products from growing large (which would push the softmax into regions with very small gradients).
q·k = Σ qᵢkᵢ has mean 0 but variance dk. Scaling brings variance back to 1, keeping softmax gradients healthy.
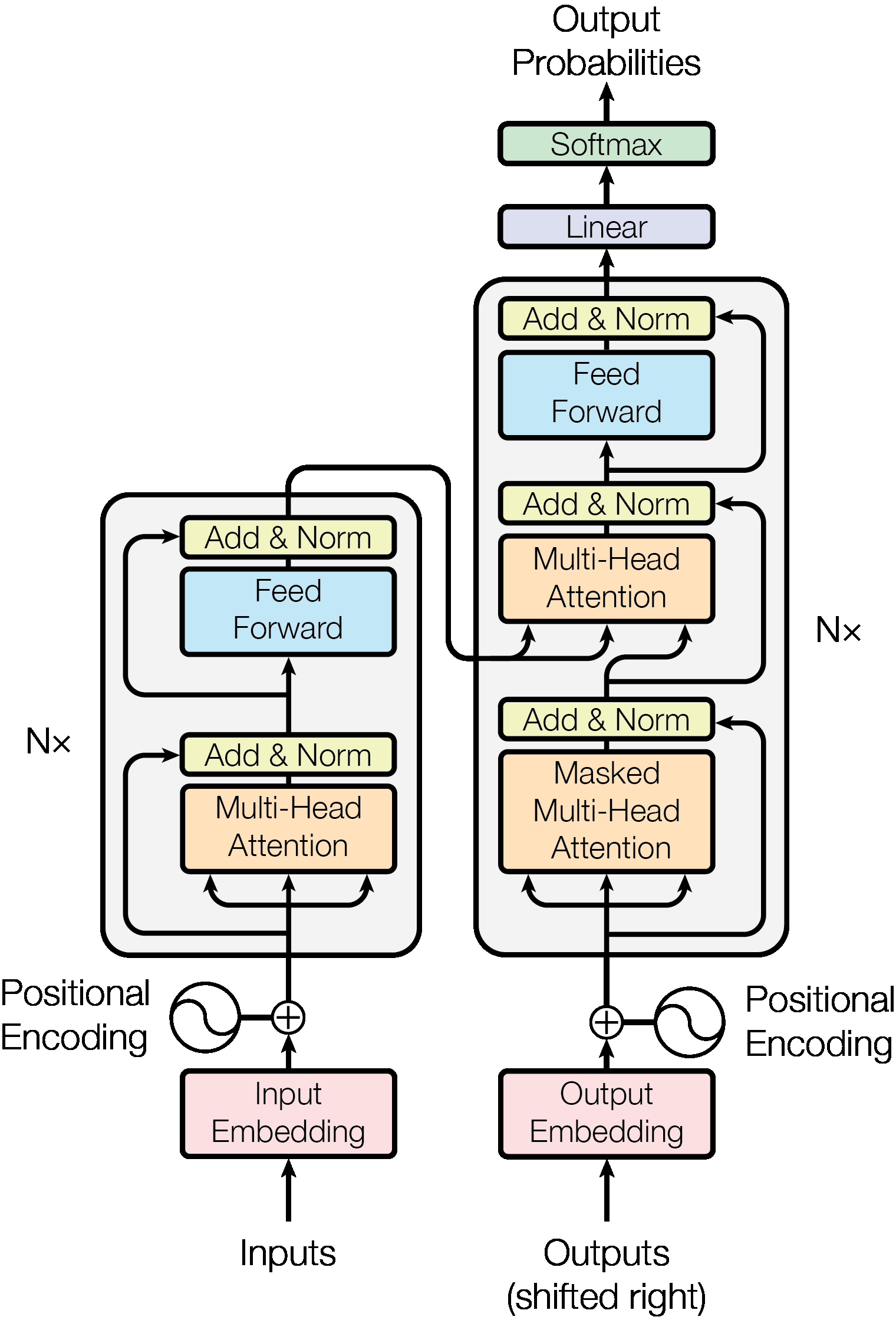
Figure 2: Scaled Dot-Product Attention — the core building block. Queries (Q), Keys (K), and Values (V) flow through MatMul, Scale, Mask, SoftMax, and MatMul to produce attention-weighted output.
3.2.2 Multi-Head Attention
Instead of one large attention function, project queries, keys and values h times with different learned linear projections, run attention in parallel, then concatenate.
where headi = Attention(QWQi, KWKi, VWVi)
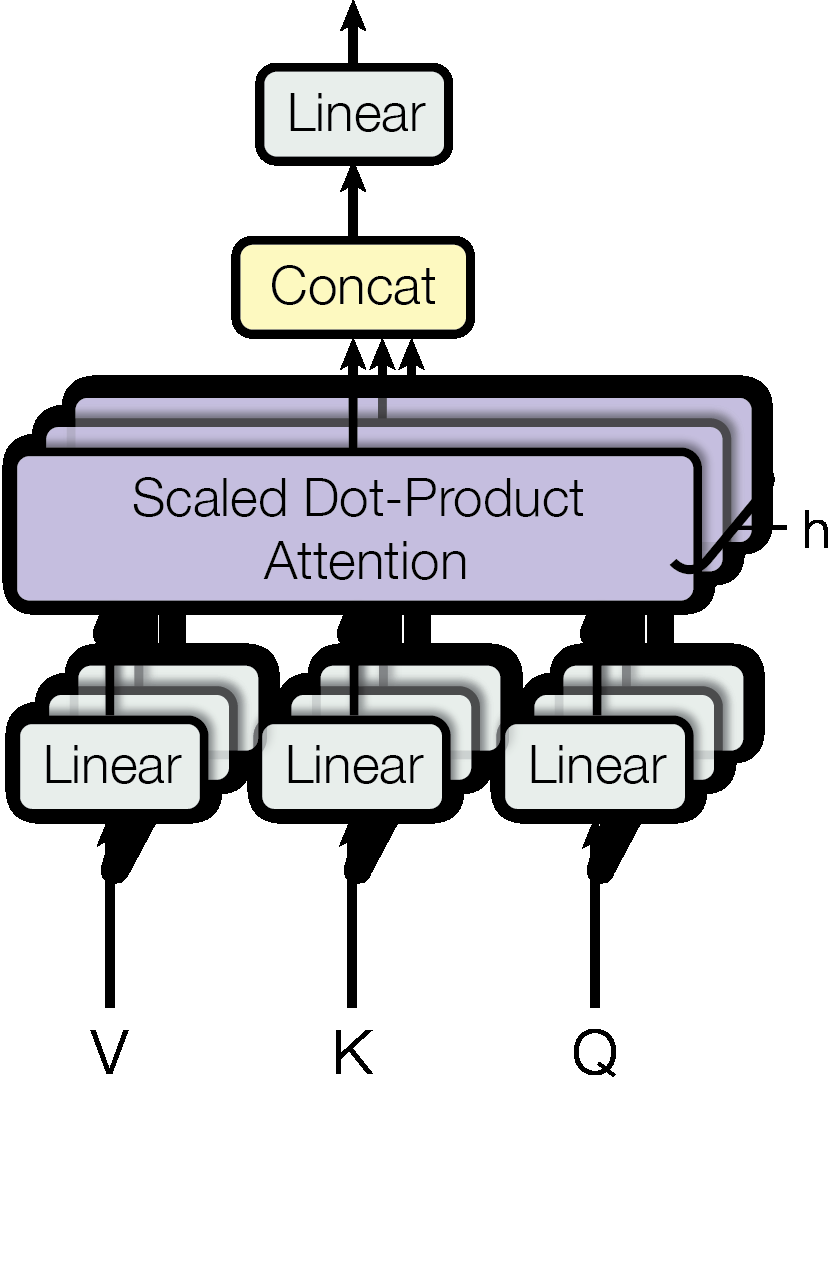
Figure 3: Multi-Head Attention — multiple attention heads (shown as parallel operations) process the input independently, then their outputs are concatenated and passed through a final linear layer.
3.2.3 Applications of Attention in the Transformer
- Encoder self-attention: Each encoder position attends to all positions in the previous encoder layer.
- Decoder masked self-attention: Each decoder position attends to all positions up to and including itself (future positions masked with −∞).
- Encoder-decoder (cross) attention: Decoder queries attend over all encoder output positions — the keys and values come from the encoder.
3.3 Position-wise Feed-Forward Networks
Each encoder/decoder layer contains a fully connected FFN applied identically to each position:
dmodel=512 on input/output; inner layer dff=2048.
3.4 Embeddings and Softmax
Learned embeddings convert tokens to dmodel-dimensional vectors. The same weight matrix is shared between: the two embedding layers and the pre-softmax linear transformation. Embedding weights are multiplied by √dmodel.
3.5 Positional Encoding
Since the Transformer has no recurrence or convolution, it has no inherent sense of token order. Positional encodings are added to input embeddings at the bottom of both encoder and decoder stacks.
PE(pos, 2i+1) = cos(pos / 100002i/dmodel)
4. Why Self-Attention
Three motivating criteria for preferring self-attention over recurrent and convolutional layers:
| Layer Type | Complexity per Layer | Sequential Ops | Max Path Length |
|---|---|---|---|
| Self-Attention | O(n² · d) | O(1) | O(1) |
| Recurrent | O(n · d²) | O(n) | O(n) |
| Convolutional | O(k · n · d²) | O(1) | O(logk(n)) |
| Self-Attn (restricted) | O(r · n · d) | O(1) | O(n/r) |
5. Training
6. Results
6.1 Machine Translation
| Model | EN-DE BLEU | EN-FR BLEU | EN-DE FLOPs | EN-FR FLOPs |
|---|---|---|---|---|
| GNMT + RL | 24.6 | 39.92 | 2.3×10¹⁹ | 1.4×10²⁰ |
| ConvS2S | 25.16 | 40.46 | 9.6×10¹⁸ | 1.5×10²⁰ |
| MoE | 26.03 | 40.56 | 2.0×10¹⁹ | 1.2×10²⁰ |
| ConvS2S Ensemble | 26.36 | 41.29 | 7.7×10¹⁹ | 1.2×10²¹ |
| Transformer (base) | 27.3 | 38.1 | 3.3×10¹⁸ | — |
| Transformer (big) | 28.4 | 41.8 | 2.3×10¹⁹ | — |
6.2 Model Variations (Ablations)
Key findings from ablation experiments (Table 3 in the paper):
- Attention heads: Single-head attention is 0.9 BLEU worse than h=8. But too many heads also hurts.
- Key dimension dk: Reducing dk hurts quality — dot-product compatibility is non-trivial.
- Bigger models are better and dropout is critical for avoiding overfitting.
- Positional encoding: Learned embeddings yield nearly identical results to sinusoidal — but sinusoidal can generalize to longer sequences.
6.3 English Constituency Parsing
To test generalization, the authors trained a 4-layer Transformer (dmodel=1024) on the WSJ Penn Treebank (~40K sentences).
7. Conclusion
The Transformer is the first sequence transduction model based entirely on attention, replacing recurrent layers with multi-headed self-attention. Key advantages:
- Significantly faster to train than RNN/CNN architectures
- Achieves new SOTA on EN-DE and EN-FR translation
- Generalizes to other tasks (constituency parsing) without task-specific modifications
Review Questions
- Why does standard RNN processing prevent parallelization, and how does the Transformer solve this?
- Derive the scaling factor
1/√dkfrom the variance argument. What happens without it? - What is the difference between encoder self-attention, decoder self-attention, and cross-attention?
- Why does the paper prefer sinusoidal positional encodings over learned embeddings?
- In Table 1 of the paper, self-attention has O(n²·d) complexity per layer. When does this become worse than recurrent layers?
- What is label smoothing and why does it hurt perplexity but improve BLEU?
- The paper uses beam search at inference. What is beam size and how does it trade off quality vs. speed?